HA-ViD
HA-VID is a human assembly video dataset that records people assembling our designed Generic Assembly Box (GAB). It is benchmarked on four foundation video understanding tasks and analyzed for its ability to comprehend application-oriented knowledge.
HA-VID stands out with three key aspects:
- Representative industrial assembly scenarios achieved via the designed GAB.
- Natural procedural knowledge acquisition process achieved by implementing the designed three-stage progressive assembly during data collection.
- Consistent human-robot shared annotations achieved via the Human-Robot Shared Assembly Taxonomy (HR-SAT) which provide detailed information on subjects, actions, manipulated objects, target objects, tools, collaboration status, pauses, and errors.
GAB
To ensure representation of real-world industrial assembly scenarios, the GAB was designed. It is a 250x250x250mm box with 35 standard and non-standard parts commonly used in industrial assembly. Four standard tools are required for assembly. The GAB includes three plates with different task precedence and collaboration requirements, providing contextual links between actions and enabling situational action understanding.
The CAD files, Bill of Materials and instructions to replicate GAB be downloaded below.
The Subject-agnostic task precedence graphs (SA-TPG) of the GAB plates can also be downloaded below as an .owl file.
Data Collection
Data was collected on three Azure Kinect RGB+D cameras mounted to an assembly workbench
facing the participant from left, front and top views.

To capture the progression of human procedural knowledge acquisition and behaviors during learning, a three-stage progressive assembly setup is designed. The stages include:
- Discovery, where participants receive minimal exploded view instructions
- Instruction, where participants receive detailed step-by-step instructions
- Practice, where participants are asked to complete the task without instruction.
The instructions provided during the discovery and instruction stages can be downloaded below.
Data Annotation
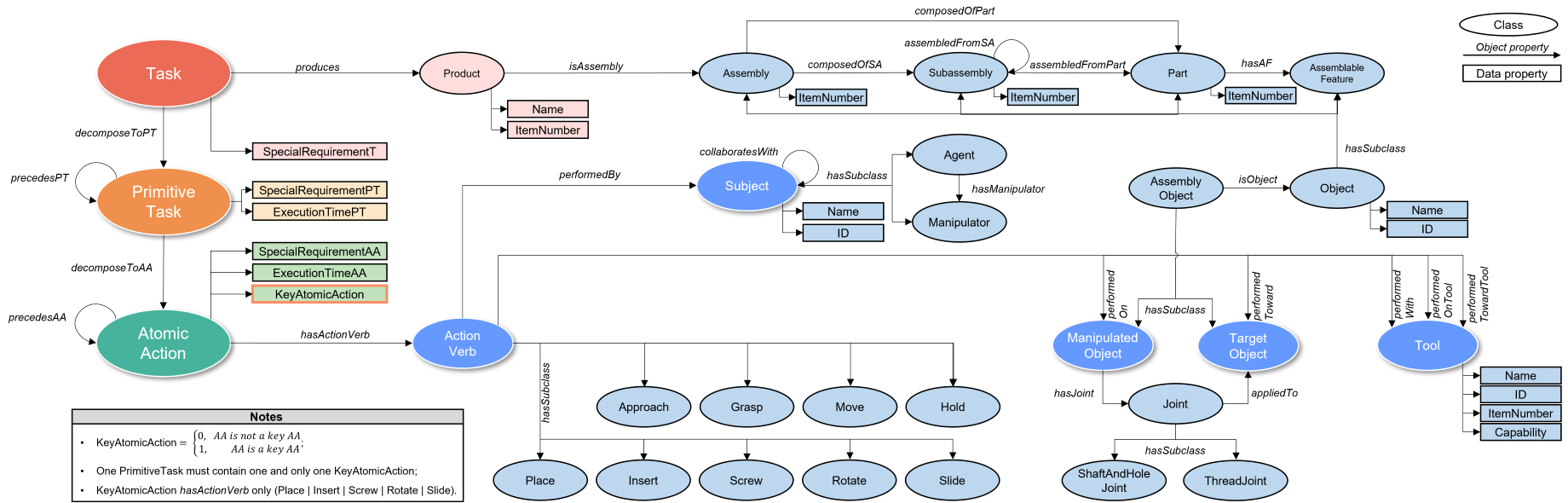
To enable human-robot assembly knowledge transfer, the structured temporal annotations are made following HR-SAT. HR-SAT ensures annotation transferability, adaptability, and consistency. The HR-SAT structure is briefly shown below.
For more information, you can visit the HR-SAT website, where you can also find the HR-SAT supplementary containing definitions of the action verbs.
The video below shows how videos were annotated with temporal annotations.
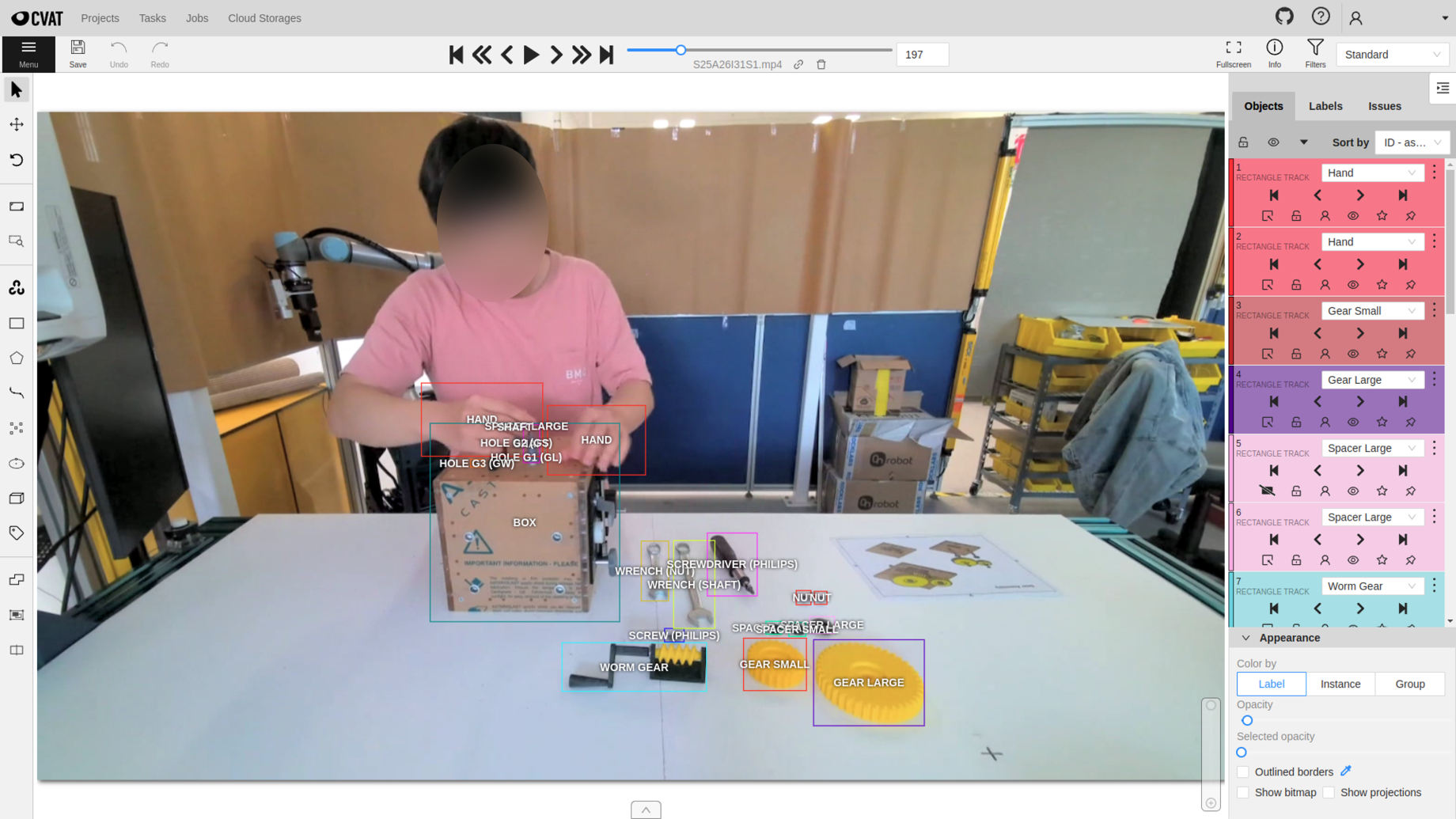
For spatial annotations, we use CVAT, a video annotation tool, to label bounding boxes for subjects, objects and tools frame-by-frame.
Acknowledgements
This project was funded by The University of Auckland FRDF New Staff Research Fund (No. 3720540)
License
HA-ViD is licensed under Creative Commons Attribution-NonCommercial 4.0 International License.
Citation
@misc{zheng2023havid,
title={HA-ViD: A Human Assembly Video Dataset for Comprehensive Assembly Knowledge Understanding},
author={Hao Zheng and Regina Lee and Yuqian Lu},
year={2023},
eprint={2307.05721},
archivePrefix={arXiv},
primaryClass={cs.CV}
}